
Weaving Programs
A soft introduction into the foundation of woven tools.

Weaving is a way of turning a single linear thread into a structured, multidimensional object. While the main brunt of programming today is built upon the bones of the structured programming movement of the early 60s, there’s still many gaping holes in the fabric of today’s code. Why is that?
I don’t really know. Sometimes I feel like idealistic programmers gazed into the abyss and the reality of a large, thousand-participant codebase gazed back and broke their ideals in a way that let them still worship them, even if depowered. Things need to be good enough in production, after all, and that means that we can have a lousy tile or loose screw here and there.
Other times, I think we focused on the large patches of wonderful fabric that we weaved correctly and gave that bit our time, disregarding the boundaries and transitions. Most bugs happen due to one boundary condition or another, and the hardest problems in programming always have to do with stepping over a divide: from the border between two languages that interfaces and types need to align and cross, to the externalization of intent that we apply when naming a variable, to literally defining a loop bound as a new limit of execution. Bounds are hard to execute correctly, and it’s where we don’t have structure, but rather a long list of infamous names… Foreign function interface. Byte array. Void pointer. Foo.
The idea for this whole topic of woven tools is to make something that a) doesn’t feel too alien to the current technological stack, doesn’t want to destroy it and start anew, but rather to infuse new life to it, and b) solves the issues of boundaries in a generic way, allowing ever more tools to sprout and come to life after a firm foundation is set.
Weave, kurzgesagt
In short, weave (aka libwv or just wv) is a library that underlies most of the efforts talked about in this blog. All the woven tools are presumed to have a basis in weave. In it’s narrowest context, what weave does is allow the distinction of data and structure in programming. Data consists of the many snippets of information that give us a full picture of some topic. Structure is how different, distinct data binds to itself - the shape it takes, the topological view of that information. Structure is, of course, only information, so it can be coerced into data. For example, a std::pair<T> in C++ is a “pair” of numbers, there’s a first and a second, but the structure of that pair is most probably simply a linear array of two, and the order of the two named elements is at best there to satisfy our intuition. We don’t imagine a pair of cherries, or twins holding hands, we’re seeing something that, as we’re getting closer to the boundary, shows itself to be the same as T[2]. If we call things a bit differently, we might find ourselves looking at a std::tuple<T>. The difference? Context, mostly.
This phenomenon is structure losing itself, becoming linear, enscribed into data. Nothing too bad— we’ve made a living out of it, after all, but it opens us up to a few questions. Did we go too far? Should everything be linearized in this way? We are losing some high-level structures, but they obviously never mattered, so why care? I say that they never mattered in the wide, open fields away from boundaries because everything is flat over there. We don’t mind boilerplate if it doesn’t increase complexity, and we hate complexity increases because they lead to bugs. Complexity can increase in two ways: data can be more complex, leading to more interspersed, diverse, linearly encoded strings, harder to parse and decode; but structure can be more complex as well, increasing the dimensionality of the whole while leaving space enough to breathe.

In essence, weave starts with a simple system quite similar to a relational database or ECS (Entity-Component-System) Framework. We have entities which are simple indices, components which carry data and are associated with entities, and then systems which is a group name for procedures that select, insert, query or otherwise manipulate entities and components. The structure we talked about above comes into play from taking a closer look at entities.
Instead of them simply being a single number, weave proposes us building every entity out of three numbers: an identifier, a source, and a target. We write “id = src → tgt”. The simplest motif built out of these have the same number for all three (id = id → id), and in this case, this is exactly the same as having only one number — this is an old-school entity in an ECS or an ID field in a database. I call these knots, to be specifically distinct from nodes. If we go further and create two of these called “a = a → a” and “b = b → b” (where “a” isn’t the same as “b”), we can now change it up and create “c = a → b”. This is a unique construction that weave lets us build and it looks pretty much exactly as you imagine it: “c” starts in “a” and leads to “b”, it’s an arrow.
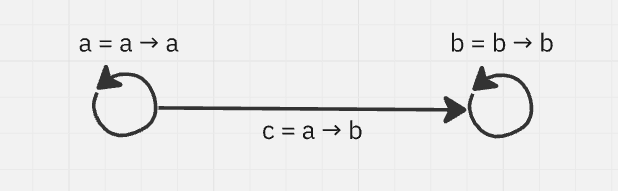
With only this simple system, we can suddenly describe simple graphs without a single component used. It’s not surprising that we ended up with directed graphs, as they’re essentially pure structure. However, weave can go some extra miles as well: there are features to graphs that are usually just convenient that spring out of our three number system!
Because there's a component storage, weave let's us attach arbitrary data to these entities, such as a position on the screen, for example.
If, say, we wanted to have a label for our graph nodes, and we wanted the label to be rendered on the graph, we’re between a rock and a hard place. On one hand, we might want to add these fields (maybe, label_string and label_position) to all nodes, but adding them to a single large component seems crude and makes the component feel bloated. Adding separate components and then adding them all to the node and filtering what to draw and how can lead to some sticky situations with ordering and priority. We want the labels to be their own thing, with their own position reusing the same position component that the node itself uses, but we can’t just add a new node for the label and add an arrow to the original node, as that would change the graph!
We need to approach this structurally: the label is dependent on the node it's presenting for, in a way, it's pointing to it. If you follow it to it's end, where does it lead? The node. That's how we know the node is it's target. Where does it begin, though? Well, in the label. In itself. label = label → node.
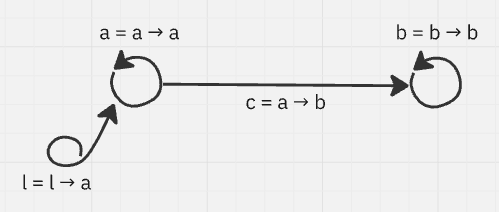
This construct isn't nodelike, nor is it arrowlike; it's something of it's own. A pointer, descriptor, mark. I've settled on mark, as it's least confusing of the bunch. The opposite of a mark is a thing that grows out of something else that it's dependent on, but firmly forms itself in the process, a child = parent → child. These ones seem good for selecting, framing and tethering hierarchies, so I call them tethers. Much more on these two in future posts, they're quite important and useful.
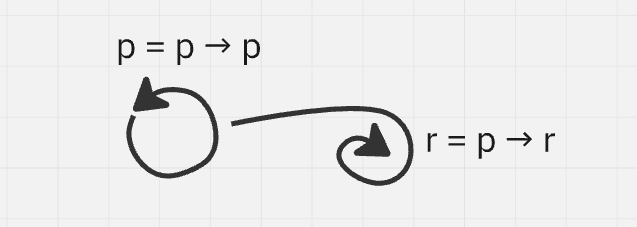
All of these differently named entities are still just entities, and we can behave with them in the exact same way. We don't need to know what “a” and “b” are to make a “c = a → b”. Maybe both of them are arrows, which would make “c” raise some eyebrows, but it's valid. We can build a lot of stuff that is very practically useful but not at all immediately recognizable as a graph or any previously familiar structure.
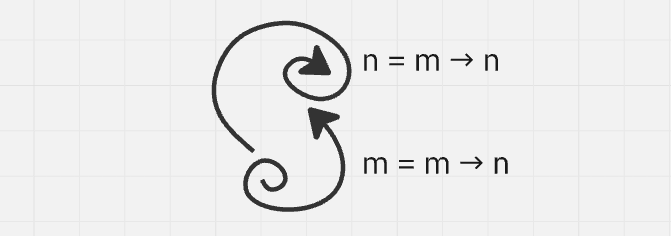
So, it’s all about graphs?
I’d be lying if I said no, but also no. It’s about graphs because graphs are data points with connections, which is the building block of informational structure. But it’s the same as someone telling you they’re building the house and you asking if it’s all about the cement. Structure yields structure, and most of it is a graph of some kind when presented with sticks and stones. On the other hand, some of our problems would be simplified if we were able to turn them to sticks and stones while preserving their context. We do visualizations and performance metrics as an afterthought. Our debugging is mostly a complex mental model and some hexes and charms to stop the compiler in a convenient spot.
Graphs (and even more so, weaves, with all the freedom to mix and match shapes) can help. We need to stop using linear tools (like your favorite logger) and understand that the underlying complex structure is there. It’s just invisible below the boundary of our processes. I’m not here to make all the cool tools, but to talk about them and hopefully inspire others to weave them into existence.
Weave is a library for just that. It enables you to make weaves, knots, arrows, marks, tethers, but also to traverse them, search, pattern match, add and delete components, and build upon them. It’s written in Rust, and cross-compiled to C, with budding libraries for C++, C#/F#, and Javascript. I’m guessing you’re here to follow these developments, in which case, stay tuned!